




























最後一戰依然棋差一著 李世石退役賽1:2不敵韓國AI「Handol」
睇嚟只有搵到BUG,先有可能擊敗AI了……
韓國職業棋手李世石於19日向韓國棋院正式遞交辭呈,宣告自己 24 年職業圍棋生涯結束。在接受韓聯社采訪時,他表示自己之所以選擇退役,是因為「AI 不可戰勝」。
李世石的職業生涯最後一站選擇了AI「Handol」作為對手,比賽在全羅道新安郡曾島 EI dorado 度假村舉行。李世石在21日的比賽中,第 181 手投子認輸。這是他與 Handol 退役賽對戰的最後一局,前兩局李世石一勝一負。最後一盤棋,他還是惜敗於 AI。

網上圖片

網上圖片
12 歲入段,36 歲正式退役,24 年攬獲 14 項國際項冠軍和 32 項國內冠軍,從此以後,「李世石九段」不會再以職業棋手的身份出現在眾人面前。他表示自己之所以選擇退役,是因為「AI 不可戰勝」:「在圍棋 AI 出現以後,我發覺即使自己成為第一名,也永遠需要面對一個不可戰勝的東西。」
中國圍棋職業選手古力九段是李世石曾經的老對手,兩人在互相競爭的時代被譽為「絕代雙驕」。古力得知李世石退役戰賽果後,在社交平台上表示:「此刻只想給他一個大大的擁抱。」
當很多人都以為李世石的最後一戰會選擇與古力上演巔峰對決時,李世石卻選擇了韓國圍棋 AI「Handol」,理由是擔心「最後和我下棋的人會有負擔」。

網上圖片
這場退役賽,是李世石自從 2016 年負於 AI「AlphaGo」 之後,再一次對戰圍棋 AI,也是人類棋手第一次與 AI下升降三番棋。
圍棋界認為頂尖人類棋手與 AI之間的差距在二子到三子之間,但由於從來沒有進行過正式比賽的對局,所以真正差距無從得知。李世石提到,自己最終選擇下升降棋,也是想確認人類和人工智能之間的差距到底有多少。
在對戰 AI「Handol」之前,李世石說自己已經有大概 5 個月的時間沒有參加過比賽,也幾乎沒有進行過圍棋訓練。

網上圖片
12 月 18 日李世石與 Handol 開始第一局對弈。李世石執黑被讓兩子,按 7 目半還子。前半盤黑棋先拿到右上角實地,勝率一直保持在 80% 以上。隨後白棋開始反擊,直到第 78 手之前,勝率一直處於上升階段。
轉折點出現在李世石的第 78 手(值得一提的是,李世石當年對戰 AlphaGo 獲勝的唯一一局,勝負手同樣是第 78 手)。黑棋吃掉白棋棋筋,加之 Handol 在第 84 手征子失誤,只得在第 92 手時投子認輸。

第 78 手,李世石再现「神之一手」。
這場比賽僅用兩小時就分出了勝負,在 100 手以內即告結束。盡管李世石表示賽前曾連續練習了十天的被讓兩子棋,「幾乎醒著的時候都在練棋」,但他也表示未能料到自己會在與 AI 的對決中獲勝。
12 月 19 日,第二局。由於李世石在第一局比賽中獲勝,第二局 Handol 不再讓子,李世石仍然執黑先行。
這一局,李世石在第 31 手出現誤判,而後白棋的勝率預測一直保持在 90% 以上,到了第 40 手以後,勝負已經基本明朗。
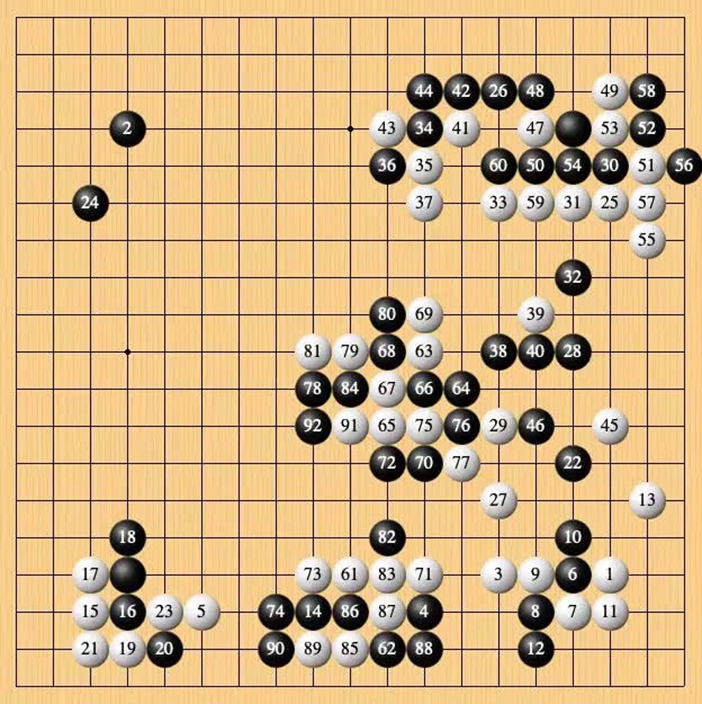
第一局的最终棋局
最終李世石在第 122 步認輸。這一局時長 3 小時 20 分鐘,至此,李世石與 Handol1:1 戰平,而剩下的最後一局尤為關鍵。
人類再次在圍棋「人機大戰」中取得了一場勝利。Google DeepMind 資深研究員、ALphaGo 主要程序開發者黃士傑博士曾在看完前兩盤對決之後表示,如果再有兩年的算法更新和優化,AlphaGo Master 將會是最強的棋手。但 AI 要做到萬無一失,仍需要解決 bug 問題。
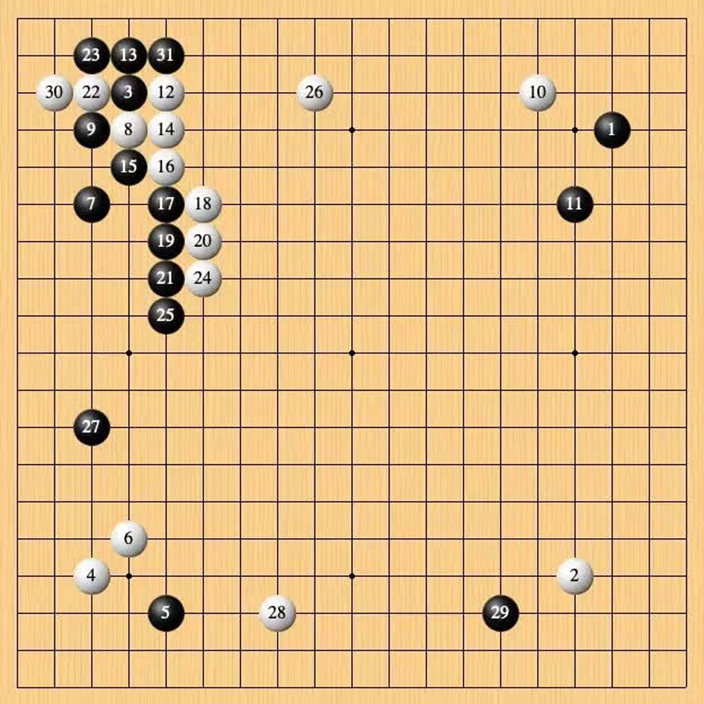
第 31 手
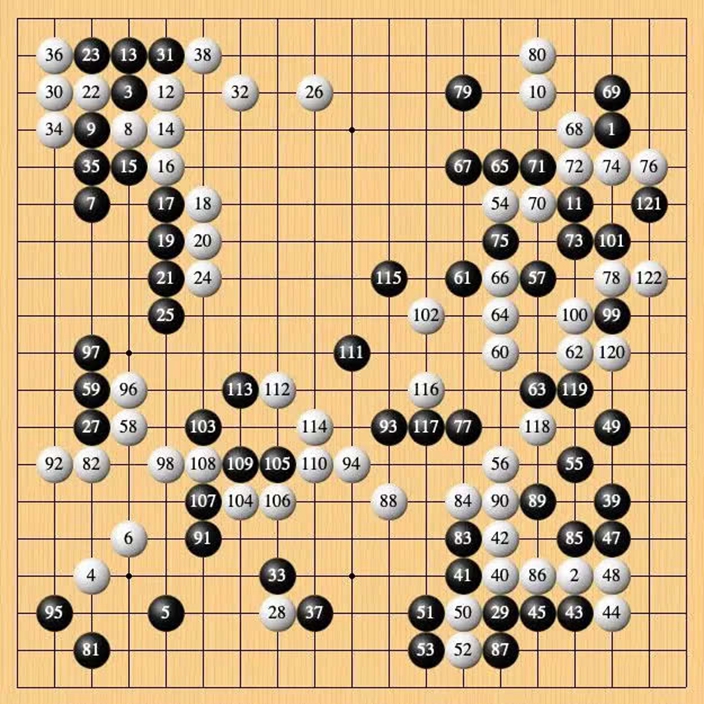
第二局的最终棋局
12 月 21 日,最後一局的賽場轉移到了李世石的家鄉全羅道新安郡。這一場李世石依然受兩子執黑挑戰 AI,黑棋貼目 7 目半。人類與 AI 在棋盤右下角展開激戰。
在最後一局中,Handol 解除了大部分限制,在每一步上花費了更多「思考」時間。AI 執白在右下角存活之後,逐漸將勝率從 20% 扳至五五開,李世石的思考時間則逐漸用盡。
下午 2 時 50 分左右,李世石進入讀秒,此時白棋已在右側和左上成活,李世石試圖通過打劫尋找 AI 的破綻。

弈至-111-手,李世石胜率降到-57.5。
賽後,李世石在接受采訪時表示:「這場比賽中,Handol 的表現與前幾場類似,如果自己能夠再謹慎一點,或許比賽的結果會有所不同。」
對於退役後的工作,李世石表示自己尚未作打算和考慮。

弈至-159-手,李世石胜率降到-5。
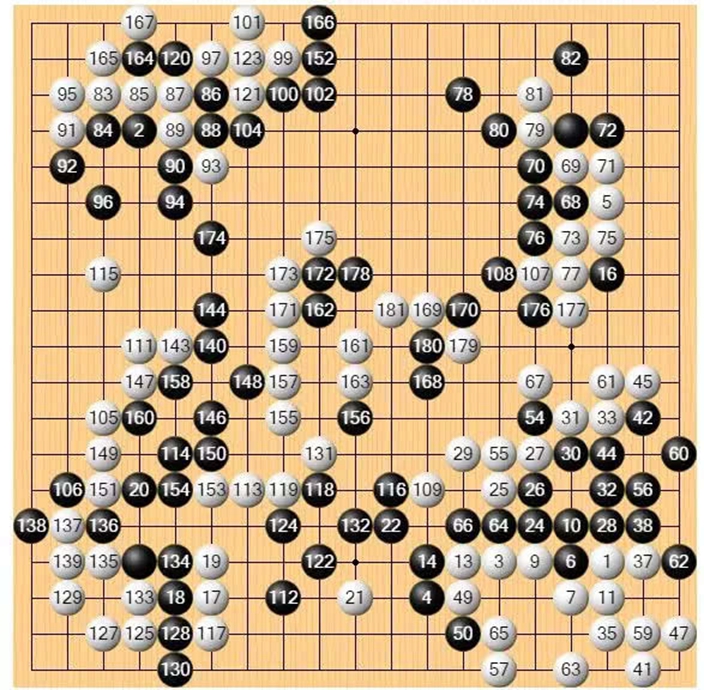
第三局最终棋局
李世石的退役消息即使來得突然,但也算早有跡象。今年 3 月份,李世石在「三一運動一百周年紀念對局」中敗於柯潔之後,即透露過自身想要「在一年之內」退役的想法。
除了沒有信心戰勝 AI,李世石的退役似乎也和自己與韓國棋院之間的矛盾分不開。在韓國棋院的 24 年中,李世石曾提交過休職申請,也強行退出過棋士會,特立獨行的處事方式與其在棋盤上的風格如出一轍。
李世石 1983 年出生在距離全羅南道新安郡的飛禽島,愛好圍棋的父親是李世石的第一任導師。6 歲開始接觸圍棋的李世石是兄弟姐妹中年齡最小的一個,但也是天賦最高的一個。9 歲時,因大哥李相勛成功入段,父親終於也下定決心將李世石送到有「韓國圍棋山脈」之稱的首爾權甲龍圍棋道場學棋。

網上圖片
3 年零 6 個月後,年僅 12 歲的李世石成功入段,從此在韓國棋院開始了職業圍棋生涯。24 年來,李世石已經獲得了 14 個國際比賽冠軍,32 次國內比賽冠軍,皆僅次於李昌鎬,高居歷史第二。
2000 年,當時的「李世石三段」在巴斯卡杯天元戰和倍達王戰中擊敗柳才馨九段和劉昌赫九段,連獲兩個冠軍,成為圍棋史上成就最高的「三段」選手。但他卻拒絕參加升段賽,聲稱「段位並不能體現實力」。為此,韓國棋界不得不廢除了升段賽,改以成績定段位。2001 年,李世石在獲得第五屆 LG 杯世界棋王賽亞軍後升至七段,2003 年獲 LG 世界棋王戰冠軍,直升九段。
李世石的圍棋生涯中曾有一次「妥協」的退役風波,2009 年 6 月,李世石曾向韓國棋院提交過休職書,稱因「韓國棋院對棋手不合理的約束」而身心疲憊,計劃從當日起休職到 2010 年底。半年後,李世石復職,但桀驁不馴的性格並未改變。2016 年,李世石又與哥哥李相勛一起,因韓國棋院「克扣獎金」的原因退出了棋士會。

網上圖片
盡管在圍棋上已經登峰造極,真正讓李世石名聲大噪的還是與 AlphaGo 的「人機大戰」。
李世石在 2016 年 3 月與 AlphaGo 的一番激戰,被認為是人工智能歷史上的一次裡程碑事件——雖然李世石以 1:4 的比分落敗,但在比賽的第四局,李世石的驚天翻盤卻讓他成為了迄今為止唯一一個戰勝過 AlphaGo 的棋手。他在第 78 手出人預料的一擠,讓 AlphaGo 後續的反應出現失常,徹底改變了戰局——這與此次在第一局中戰勝 Handol 的場面何其相似。
李世石面對 AlphaGo 的那一次勝利,曾經為人類戰勝人工智能帶來了一線希望,但後來李世石將勝利歸功於 AlphaGo 程序的缺陷。「我的第 78 手並不應該用直接的方式應對。」

網上圖片
當然,這樣的 bug 不止存在於 AlphaGo。李世石曾說:「在騰訊AI『絕藝』中,這樣的 bug 至今仍然會出現。即使現在的絕藝已經可以做到讓人類兩子勝利了,但它仍然會以奇怪的方式輸掉比賽,這是因為一個 bug 所致。」
在前三場比賽輸給 AlphaGo 之後,他曾感到相當沮喪。「我很少看網上對我的評論,但是輸給了AlphaGo以後,我很好奇大家怎麼看我。意外的是,很少有人批評我。」
這一次對戰 Handol,李世石賺了 2 億韓元(約合 121 萬元人民幣),包括 1 億 5000 萬韓元的基本出場費,每勝一局額外獲得 5000 萬韓元的獎金。
自從 2016 年 AlphaGo 大戰李世石之後,圍棋 AI 即被推上風口浪尖。基於近年以來深度學習和強化學習的發展,AlphaGo 和各類圍棋 AI 的不斷升級,人們一度認為,人類再不可能戰勝 AI。
Handol 是韓國 NHN 娛樂公司推出的一款圍棋 AI,用以訓練的數據來自 1999 年以來 NHN 公司在游戲業務方面的大量積累。與 AlphaGo 的進化路線相似,2017 年 12 月,Handol1.0 出世,當時已擁有人類職業棋手 9 段棋力,可以實現在人類棋譜及既定模式的基礎上對棋局進行預測,到了 Handol 2.0 已經能夠脫離棋譜,自己與自己下棋。在 NHN 看來,Handol2.1 的實力已經超越了當初對戰李世石的 AlphaGo。
2019 年 1 月,Handol 連續戰勝了申旻埈九段、李東勛九段、金智碩九段、樸正煥九段和申真瑞九段五位韓國頂級圍棋選手,8 月在山東舉行的「中信證券杯」世界智能圍棋公開賽中,Handol 也捧回了季軍獎杯。
在「Handol」首局落敗之後,NHN 公司人工智能項目的負責人李昌律推測稱,「輸掉這一局的原因 kennel 在於「Handol」總體學習量尚且不足,缺少對開局讓兩子和讓三子等棋局的學習」。
據「Handol」研發團隊估算,「Handol」的棋力水平相當於世界圍棋中的 4500 積分,而目前李世石的積分為 3414 分,柯潔、樸廷桓等人類頂尖棋手的積分接近 3700 分。
在圍棋 AI 領域,棋力最高的選手仍然是 DeepMind 公司的 AlphaGo,它也是第一個擊敗人類圍棋世界冠軍的人工智能程序。在 2017 年柯潔與 AlphaGo 對戰之後,David Silver、谷歌大腦負責人 Jeff Dean 等人曾在烏鎮圍棋峰會現場對 AlphaGo 背後的技術進行過解讀。
AlphaGo 最初主要是依靠大量學習人類棋手的棋譜來提高棋藝,之後 進入到完全的自我深度學習階段,也就是完全摒棄人類棋手的思維方式,按照自己(左右互搏)的方式研究圍棋。結合監督學習與強化學習的優勢,AlphaGo 通過訓練形成一個策略網絡,將棋盤上的局勢作為輸入信息,並對有所可行的落子位置形成一個概率分布。然後訓練一個價值網絡對自我對弈進行預測,以-1(對手的絕對勝利)到 1(AlphaGo 的絕對勝利)的標准,預測所有可行落子位置的結果。
AlphaGo 真正的優勢來源於將策略網絡和價值網絡整合進基於概率的蒙特卡羅樹搜索(MCTS)中。在獲取棋局信息後,AlphaGo 會根據策略網絡探索哪個位置同時具備高潛在價值和高可能性,進而決定最佳落子位置。在分配的搜索時間結束時,模擬過程中被系統最繁瑣考察的位置將成為 AlphaGo 的最終選擇。經過先期的全盤探索和過程中對最佳落子的不斷揣摩,AlphaGo 的探索算法就能在其計算能力之上加入近似人類的直覺判斷。2016 年 1 月 28 日,擊敗李世石的 AlphaGo 版本登上《Nature》封面,隨後在 3 月即 4:1 擊敗李世石,名聲大振。
和人類不同,AlphaGo 沒有先入為主的概念,這恰恰也是所有圍棋 AI 的優勢所在:盡管有時 AI 的落子顯得違反直覺,但確實是最合理的。
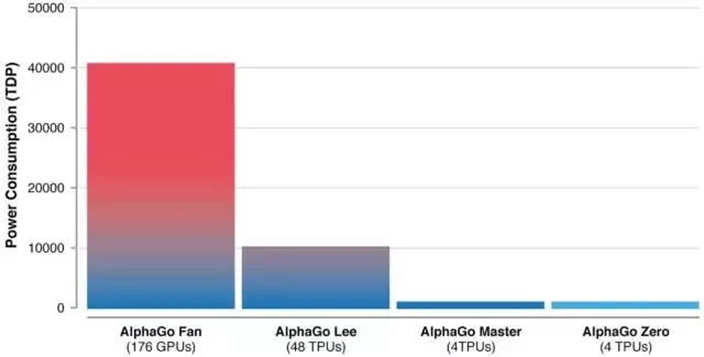
烏鎮之後,DeepMind 宣布 AlphaGo 從此不會再參與比賽,但在幾個月後推出了更強版本的圍棋 AI「AlphaGo Zero」。如果說 AlphaGo 版本最初還需要觀察數千場人類圍棋比賽來訓練如何學習圍棋,AlphaGo Zero 則直接跳過這一步,從自己完全隨機的下圍棋開始來學習圍棋,幾天之內即超越人類棋手的水平,並且以 100:0 的比分打敗了之前戰勝世界冠軍的 AlphaGo。
早期的 AlphaGo 使用「決策網絡」選擇下一步棋的位置,使用「價值網絡」預測每一個位置上決定的勝者。這兩個網絡在 AlphaGo Zero 中被結合起來,從而使其更高效地訓練和評估賽況。並且,AlphaGo Zero 版本只需 4 塊 TPU 即可運行。
上個月,DeepMind 又推出了名為 MuZero 的「通用版」AlphaGo,在國際像棋、日本將棋和圍棋的精確規劃任務中可以匹敵 Alpha Zero,在圍棋中甚至超過了 Alpha Zero。但與前輩不同的是,MuZero 不需要提前獲知規則。
網上圖片
在圍棋 AI 領域,國內研究機構和企業也在發力,其中最有代表性的要數上文中李世石提到的騰訊圍棋 AI「絕藝」。「絕藝」誕生於 2016 年,實力或僅次於 AlphaGo。
「絕藝」的訓練主要包括人類棋譜數據庫和機器自對弈,它的算法基於策略網絡與價值網絡兩大核心,並創新性地大幅提升了價值網絡的精度,使其大局觀表現更好。在 2018 騰訊世界人工智能圍棋大賽中,「絕藝」在決賽中 7:0 大勝另一款圍棋 AI「星陣」奪冠,半決賽五番棋和決賽七番棋不失一局,賽後「星陣」研發團隊亦稱贊「絕藝」已經「達到了 AlphaGo 的水准」。
雖然在圍棋的算力上,人類已經難以與機器相比,但棋手們可以通過與 AI 的對弈不斷提升自己的水平,甚至發展出更為先進的戰術。據古力此前透露,「絕藝」已經成為中國國家圍棋隊訓練專用 AI。






